Four Useful Python Libraries You Don't Know About
by IoFAdmin at
python | programming

4 Obscure Python Libraries
In this post, I thought I'd try something different. I picked 4 Python libraries that you probably haven't heard of that I find useful. I'll show you how to use them and then we'll make a fun little program with them.
Jump Ahead Links
Great Scott Marty! Introducing Delorean
You mean Delorean is more than a time-traveling car? Yes, random Internet Stranger, it is. Datetime objects in Python can be a little difficult to work with. Delorean is a library that makes dealing with Datetime objects easier.
According to the documentation, Delorean is a library for clearing up the inconvenient truths that arise dealing with datetimes in Python. Understanding that timing is a delicate enough of a problem delorean hopes to provide a cleaner less troublesome solution to shifting, manipulating, generating datetimes.
Fire Up the Flux Capacitor
Since the docs for Delorean are pretty good, so I won't go into a lot of detail here. Below are a few examples of using it. (You can run these yourself in your Python interpreter or IDE.) Buy your Flux Capacitor before you start.
from delorean import Delorean
# create delorean obj
d = Delorean()
d
# set obj to central timezone
d = d.shift("US/Central")
d
# print datetime
d.datetime
# print date
d.date
In the example above, we create a Delorean object, set it to Central timezone and then print it's datetime and date values.
# create obj d = Delorean() d # print next tuesday's date d.next_tuesday() # print datetime two tuesdays ago at midnight d.last_tuesday(2).midnight
In our second example, we print the datetime of next Tuesday based on the current date set by Delorean. Finally we count back to 2 previous Tuesdays and get the datetime at midnight. That would've been painful to do manually.
Bears and Fuzzy Pattern Matching. Introducing FuzzyWuzzy
Our next library, FuzzyWuzzy, gives us a way to easily fuzzy match strings. Fuzzy matching involves comparing an input to a variety of values and computing their amount of "sameness". The FuzzyWuzzy documentation gives more information.
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
fuzz.ratio("this is a test", "this is a test!")
fuzz.partial_ratio("this is a test", "this is a test!")
fuzz.token_sort_ratio("fuzzy was a bear", "fuzzy fuzzy was a bear")
choices = ["Atlanta Falcons", "New York Jets", "New York Giants", "Dallas Cowboys"]
process.extract("new york jets", choices, limit=2)
process.extractOne("cowboys", choices)
With fuzz.ratio, we compare "this is a test" to "this is a test!" which gives us a score of 97 (97% the same). fuzz.partial_ratio, scoring on the first string existing in the second, gives us 100 because 100% of the first string exists in the second. fuzz.token_sort_ratio, using "tokens" to compare the first set of words compared to the second, gives us a score of 84.
The second section of the code compares the first string to matches in a list of strings. process.extract returns a list of tuples containing the matched string from the list and the score. (limit sets the number of matches returned.) process.extractOne does the same thing but only returns one match which is always the best match (highest score).
Wink, Smile, Thumbs Up. Introducing Emoji
Emoji is a Python library that unsurprisingly allows us to display emojis. Emoji's documentation is easy to follow but it doesn't give much detail.
import emoji
print(emoji.emojize('Python is :thumbs_up:'))
print(emoji.emojize('Python is :thumbsup:', use_aliases=True))
print(emoji.emojize("Python is fun :red_heart:"))
print(emoji.emojize("Python is fun :red_heart:",variant="emoji_type"))
There's not much to Emoji but it does its job well. emoji.emojize replaces any emoji code with the actual emoji symbol. use_aliases=True allows you to use alternate names for the emoji (:thumbs_up: vs :thumbsup:). variant seems to force your computer to load an actual emoji in the terminal instead of an ascii code character. (That's just a guess based on my experimenting with it but it doesn't say anything in the docs.)
The Last Stop On Our Magical Mystery Tour. Introducing Inflect
Inflect is a bit harder to explain because it does a lot. It's a toolbox that helps us build messages/sentences to display to the user that are "smart". If you give Inflect a verbs, nouns or adjectives, it's smart enough to return the correct version of the word. For example the plural form of "dog" is "dogs". Inflect also allows you to switch numbers (1, 100, 1000) to words (one, one hundred, one thousand).
import inflect
inflector = inflect.engine()
num_words = inflector.number_to_words(1632976)
num_words
num_turkeys = 1
print("I saw", num_turkeys, inflector.plural(word, num_turkeys))
num_turkeys = 17
print("I saw", num_turkeys, inflector.plural(word, num_turkeys))
n1 = 1
n2 = 2
print(
inflector.plural_noun("I", n1),
inflector.plural_verb("saw", n1),
inflector.plural_adj("my", n2),
inflector.plural_noun("saw", n2)
)
Let's Build A Project!
Now that we've seen how to use these libraries, let's put them all together to build a mini project. Our project is going to be a very small version of MadLibs. I'll show you the code and then give a tiny bit of explanation.
import random
from datetime import timedelta
import delorean
import emoji
import inflect
from delorean import Delorean
from fuzzywuzzy import process
class Story:
verbs = ['runs', 'swims', 'walks', 'flies', 'paints', 'sleeps', 'eats', 'drives', 'spells', 'bakes', 'slices', 'waters']
nouns = ['taco', 'elephant', 'cheeseburger', 'shoe', 'ogre', 'broccoli', 'lightbulb', 'cloud', 'coffee', 'mailbox', 'slime', 'hat']
descriptors = ['green', 'tired', 'huge', 'sleepy', 'delicious', 'stinky', 'funky', 'hairy', 'moldy', 'expensive', 'wet', 'droopy']
places = ['house', 'stadium', 'theater', 'store', 'bakery', 'amusement park', 'canyon', 'moon', 'valley', 'circus tent', 'forest', 'mountain']
subjects = {
0: ['boy', 'girl', 'rabbit', 'platypus', 'astronaut', 'horse', 'alligator', 'clown', 'dentist', 'beekeeper', 'mushroom', 'monster'],
1: ['candle', 'toe', 'headache', 'spoon', 'cat', 'toaster', 'racecar', 'baseball', 'toothbrush', 'towel', 'sandbox', 'grampa']
}
adjectives = ['this', 'that', 'a', 'my', 'your', 'his', 'her', 'the']
prepositions = ['at', 'in', 'under', 'beside', 'behind', 'above', 'from']
intervals = ['minutes', 'hours', 'days', 'weeks']
feelings = {'sad': ':frowning:', 'happy': ':smile:', 'tired': ':tired_face:', 'sleepy': ':sleepy:', 'angry': ':angry:', 'worried': ':worried:', 'confused': ':confused:', 'disappointed': ':disappointed:', 'amazed': ':open_mouth:'}
lunch_stuff = ['Chicken Tacos', 'Cheeseburgers', 'Steamed Broccoli', 'Black Coffee']
num_stories = 1
def __init__(self, num_stories = 1):
self.inflector = inflect.engine()
self.num_stories = num_stories
def about_lunch(self, noun):
if process.extractOne(noun, self.lunch_stuff)[1] >= 75:
return 'is'
return 'isn\'t'
def random_emotion(self):
emotion = random.choice(
list(self.feelings)
)
return (
emotion,
self.emoji_by_emotion(emotion)
)
def emoji_by_emotion(self, emotion):
selected_emoji = self.feelings.get(emotion)
return emoji.emojize(selected_emoji, use_aliases=True)
def single_or_plural(self):
num = random.randint(1, 10000)
if num % 2 == 0:
return 1
return 2
def random_number(self):
num = random.randint(1, 10000)
if num % 3 == 0:
return 1
return num
def number_to_words(self,num):
return self.inflector.number_to_words(num)
def random_preposition(self):
return random.choice(self.prepositions)
def random_descriptor(self):
return random.choice(self.descriptors)
def random_place(self):
return random.choice(self.places)
def random_subject(self, idx, num):
return self.inflector.plural_noun(
random.choice(self.subjects.get(idx)),
num
)
def random_adjective(self, num):
adjective = random.choice(self.adjectives)
if num == 1:
return adjective
return self.inflector.plural_adj(adjective)
def random_noun(self, num):
noun = random.choice(self.nouns)
if num == 1:
return noun
return self.inflector.plural(noun)
def random_verb(self, num):
return self.inflector.plural_verb(
random.choice(self.verbs), num
)
def adjective_subject_verb(self, subject_idx):
num = self.single_or_plural()
return [
self.random_adjective(num),
self.random_subject(subject_idx, num),
self.random_verb(num)
]
def adjective_subject_place(self, subject_idx):
num = self.single_or_plural()
subject = self.random_subject(subject_idx, num)
if num == 2:
subject += '\''
else:
subject += '\'s'
return [
self.random_adjective(num),
subject,
self.random_place()
]
def adjective_num_descriptor_noun(self):
num = self.random_number()
return [
self.random_adjective(num),
self.number_to_words(num),
self.random_descriptor(),
self.random_noun(num)
]
def timeframe(self):
self.delorean = Delorean()
self.delorean = self.delorean.shift("US/Central")
interval = random.choice(self.intervals)
num = random.randint(1, 10)
self.delorean += timedelta(
**{interval: num}
)
out = f'In {num} {interval}, it will be {self.delorean.datetime.strftime("%a %b %d, %Y %I:%M %p")}'
return out
def capitalize_sentences(self, orig):
sentences = orig.split(". ")
sentences2 = [sentence[0].capitalize() + sentence[1:] for sentence in sentences]
return '. '.join(sentences2)
def create_story(self):
part1 = self.adjective_subject_verb(0)
part2 = self.adjective_num_descriptor_noun()
part3 = self.adjective_subject_place(1)
preposition = self.random_preposition()
time = self.timeframe()
(emotion, feeling) = self.random_emotion()
lunch = f'The first sentence {self.about_lunch(part2[3])} about lunch.'
out = self.capitalize_sentences(f"{' '.join(part1)} {' '.join(part2)} {preposition} {' '.join(part3)}.\n{time}.\nI\'m {feeling} {emotion}.\n{lunch}\n\n")
print(out)
if __name__ == '__main__':
story_maker = Story(
int(input('How many stories: '))
)
for i in range(story_maker.num_stories):
story_maker.create_story()
Explanation
This post has gotten pretty long so I'm not going to explain the code in a lot of detail. If you have specific questions, please ask them in the comment section below.
Basic Overview
- Input: Ask the user for how many "stories" he/she wants to create.
- Random adjective, subject, verb: Select whether noun is singular or plural and randomly get an adjective, subject and verb with the correct choice of singular or plural.
- Get more random words: Randomly select an adjective, number, descriptor and noun.
- Pick another random adjective, subject and place: You know the drill by now.
- Preposition: Randomly choose a preposition from our list.
- Use our Delorean object: Set the timezone and randomly set a time in the future.
- Express yourself: Pick a random feeling and an associated emoji.
- Does the first sentence contain a food word? Fuzzy match the first sentence against our list of food words.
- Capitalization: Concatenate all of the sentences together and capitalize the first word of each one.
- Display: Print out the result.
- Repeat: Continue the process for each other story we need to create.
Support This Site By Buying Me A Coffee!
If you find this tutorial helpful, please consider buying me a coffee. Thanks!
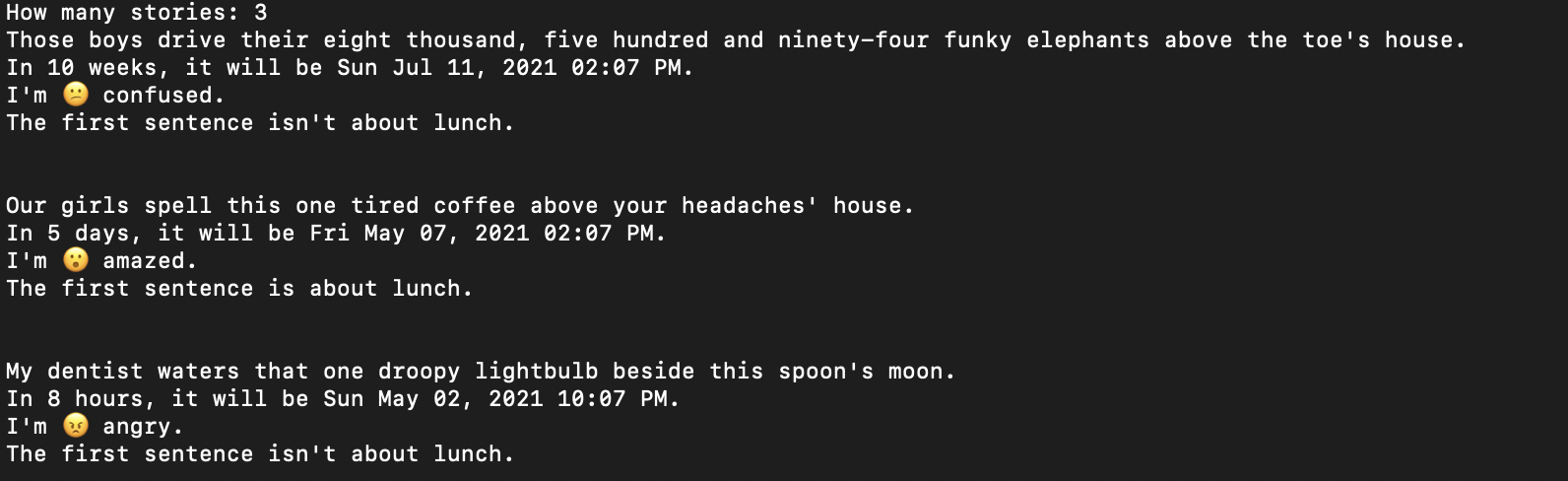
Sample Output